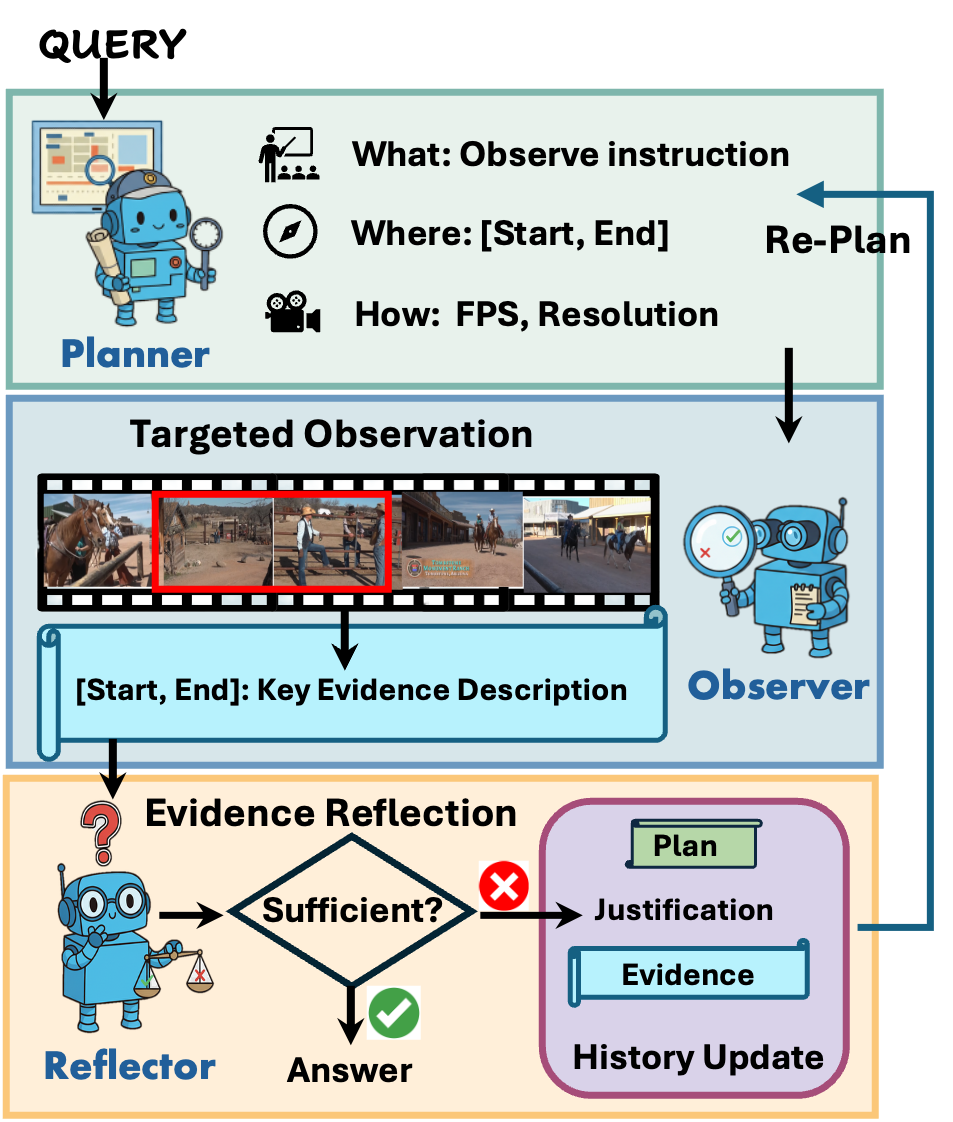
Motivation
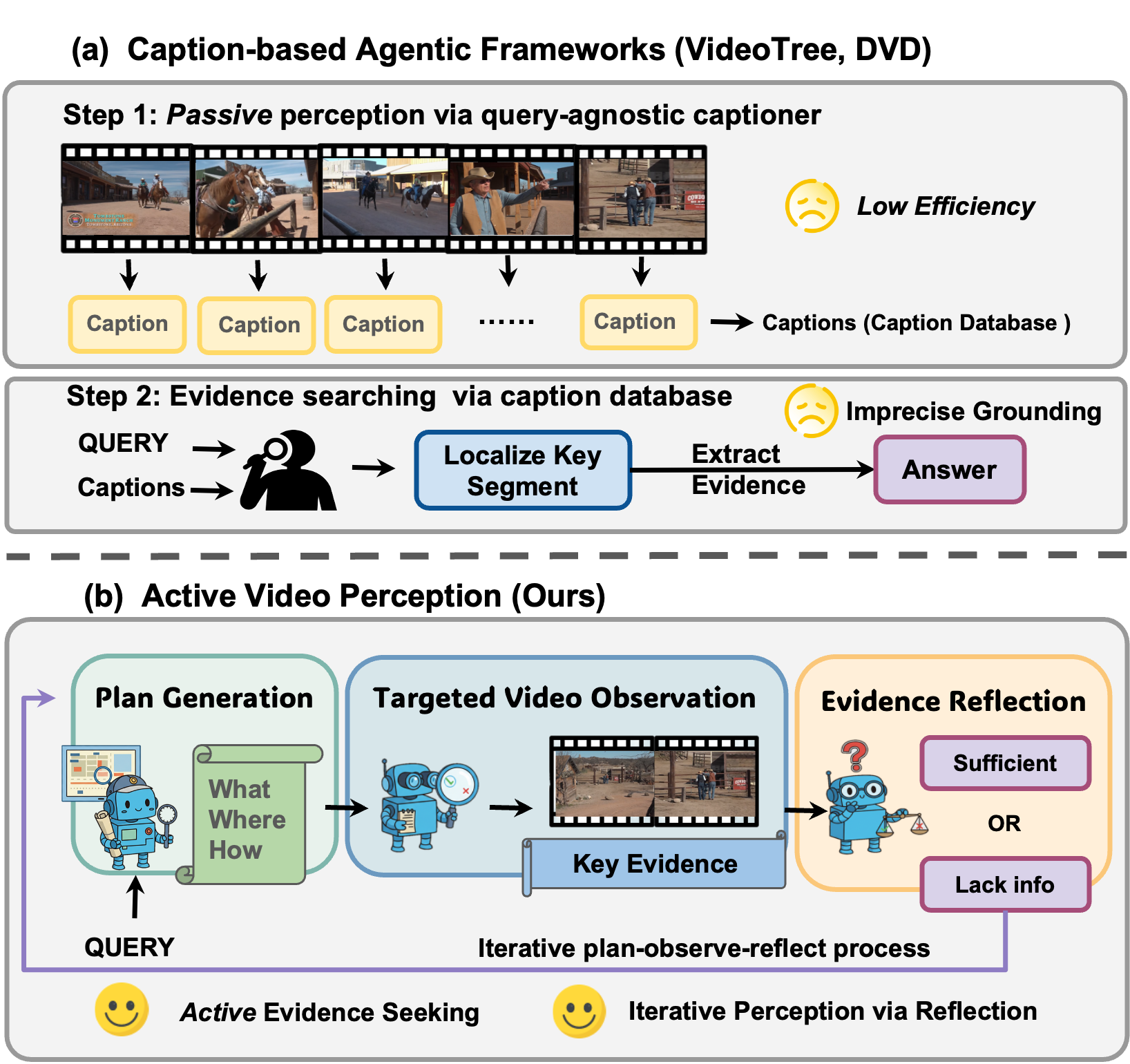
Motivation of Active Video Perception.
Prior methods follow a passive perception paradigm that leverages
query-agnostic captioners to perceive video information, leading to low
efficiency and imprecise visual grounding. Instead, our model AVP
actively perceives query-relevant content by treating the long video
as an interactive environment to be explored in a goal-directed manner.